For the examples below, we'll be using a dataset from the ggplot2 package called msleep. It has 83 rows, with each row including information about a different type of animal, and 11 variables. As each row is a different animal and each column includes information about that animal, this is a wide dataset. So, the aggregation function takes at least three numeric value arguments. First one is formula which takes form of y~x, where y is numeric variable to be divided and x is grouping variable. The input parameter for this data aggregation must be a data frame, or the query will return null or missing values instead of sourcing the correct grouping elements.

If you have a vector, you must convert it to dataframe and then use it. Example 3-13 demonstrates stratified sampling, in which rows are selected within each group where the group is determined by the values of a particular column. The example creates a data set that has each row assigned to a group. The argument 4 is the desired mean for the distribution.
The example splits the data according to group and then samples proportionately from each partition. Finally, it row binds the list of subset ore.frame objects into a single ore.frame object and then displays the values of the result, stratifiedSample. You can summarize data by using the aggregate function, as shown in Example 3-6. The example pushes the iris data set to database memory as the ore.frame object iris_of. It aggregates the values of iris_of by the Species column using the length function. To demonstrate how to combine several factor levels into a single level, we'll continue to use our 'chickwts' dataset.

Now, I don't know much about chicken feed, and there's a good chance you know a lot more. How to create a frequency table with the dplyr package R programming example Our example data frame consists of 100 rows and two columns. A tibble containing each possible combination of our two variables x and y as well as the count of Note that the previous R code is based on this thread on Stack Overflow. Example 3-17 illustrates some of the statistical aggregation functions. For a data set, the example first generates on the local client a sequence of five hundred dates spread evenly throughout 2001.

It then introduces a random difftime and a vector of random normal values. The example then uses the ore.push function to create MYDATA, an in-database version of the data. The example invokes the class function to show that MYDATA is an ore.frame object and that the datetime column is of class ore.datetime. The example displays the first three rows of the generated data.

It then uses the statistical aggregation operations of min, max, range, median, and quantile on the datetime column of MYDATA. Loading this package makes a data frame called flights, which includes "on-time data for all flights that departed NYC in 2013," available. We will work with this dataset to demonstrate how to create a date and date-time object from a dataset where the information is spread across multiple columns. To get an idea of what variables are included in this data frame, you can use glimpse(). This function summarizes how many rows there are and how many columns there are .

Additionally, it gives you a glimpse into the type of data contained in each column. You can select portions of a data set, as shown in Example 3-3. The example pushes the iris data set to the database and gets the ore.frame object iris_of. It filters the data to produce iris_of_filtered, which contains the values from the rows of iris_of that have a petal length of less than 1.5 and that are in the Sepal.Length and Species columns. Now that we've made the data easier to work with, we need to find a way to get the median. One method is to take the cumulative sum of each column and then divide all the rows by the last row in each respective column, calculating a percentile/quantile for each age.

To do this, we first remove the AGE column, as we don't want to calculate the median for this column. We then apply the cumsum() function and an anonymous function using purrr's map_dfc function. This is a special variation of the map() function that returns a dataframe instead of a list by combining the data by column. But, of course, we do still want the AGE information in there, so we add that column back in using mutate() and then reorder the columns so that AGE is at the front again using select(). Example 3-22 uses the window functions ore.rollmean and ore.rollsd to compute the rolling mean and the rolling standard deviation. The example uses the MYDATA ore.frame object created in Example 3-17.

How To Group By Two Columns The example ensures that MYDATA is an ordered ore.frame by assigning the values of the datetime column as the row names of MYDATA. The example computes the rolling mean and the rolling standard deviation over five periods. Next, to use the R time series functionality in the stats package, the example pulls data to the client.

To limit the data pulled to the client, it uses the vector is.March from Example 3-19 to select only the data points in March. The example creates a time series object using the ts function, builds the Arima model, and predicts three points out. In the above we use the pipe to send the surveys data set first through filter, to keep rows where weight was less than 5, and then through select to keep the species and sex columns. When the data frame is being passed to the filter() and select() functions through a pipe, we don't need to include it as an argument to these functions anymore. Sometimes it is valuable to apply a certain operation across the columns of a data frame. For example, it be necessary to compute the mean or some other summary statistics for each column in the data frame.
In some cases, these operations can be done by a combination of pivot_longer() along with group_by() and summarize(). However, in other cases it is more straightforward to simply compute the statistic on each column. Dplyr and R in general are particularly well suited to performing operations Calling a function multiple times with varying arguments.

When combined with rowwise it also makes it easy to summarise values across columns within one row. Imagine you have this data frame and you want to count the lengths of each. The ore.esm function builds a simple or a double exponential smoothing model for in-database time series observations in an ordered ore.vector object. The function operates on time series data, whose observations are evenly spaced by a fixed interval, or transactional data, whose observations are not equally spaced. The function can aggregate the transactional data by a specified time interval, as well as handle missing values using a specified method, before entering the modeling phase.

Many of the examples of the exploratory data analysis functions use the NARROW data set. NARROW is an ore.frame that has 9 columns and 1500 rows, as shown in Example 3-23. To get objects into dates and date-times that can be more easily worked with in R, you'll want to get comfortable with a number of functions from the lubridate package. Below we'll discuss how to create date and date-time objects from strings and individual parts. You will often find when working with data that you need an additional column.

For example, if you had two datasets you wanted to combine, you may want to make a new column in each dataset called dataset. This way, once you combined the data, you would be able to keep track of which dataset each row came from originally. More often, however, you'll likely want to create a new column that calculates a new variable based on information in a column you already have. For example, in our mammal sleep dataset, sleep_total is in hours.

You could create a new column with this very information! The function mutate() was made for all of these new-column-creating situations. The example uses the datetime column of the MYDATA ore.frame object created in Example 3-17. Example 3-19 selects the elements of MYDATA that have a date earlier than April 1, 2001. The resulting isQ1 is of class ore.logical and for the first three entries the result is TRUE.

The example finds out how many dates matching isQ1 are in March. It then sums the logical vector and displays the result, which is that 43 rows are in March. The example next filters rows based on dates that are the end of the year, after December 27.
The example displays the first three rows returned in eoySubset. It first creates a temporary database table, with the corresponding proxy ore.frame object iris_of, from the iris data.frame object. The example selects two columns from iris_of and creates the ore.frame object iris_projected with them.
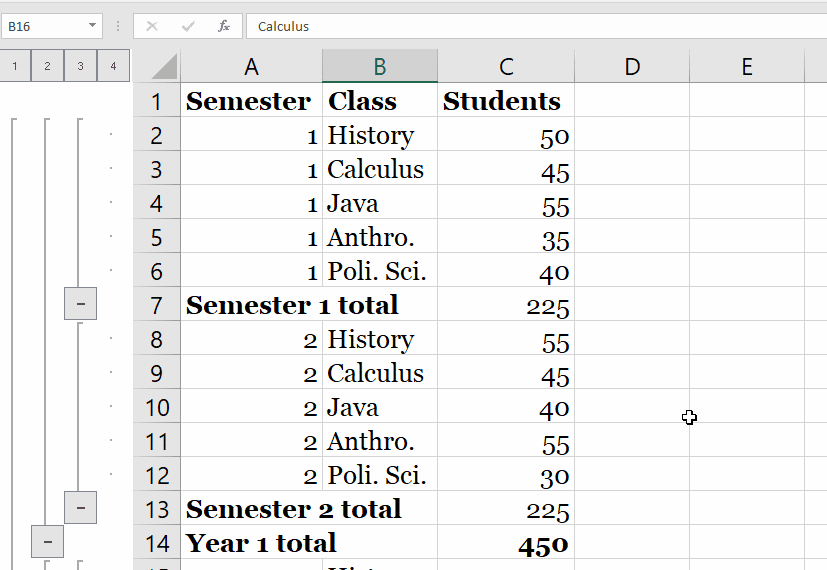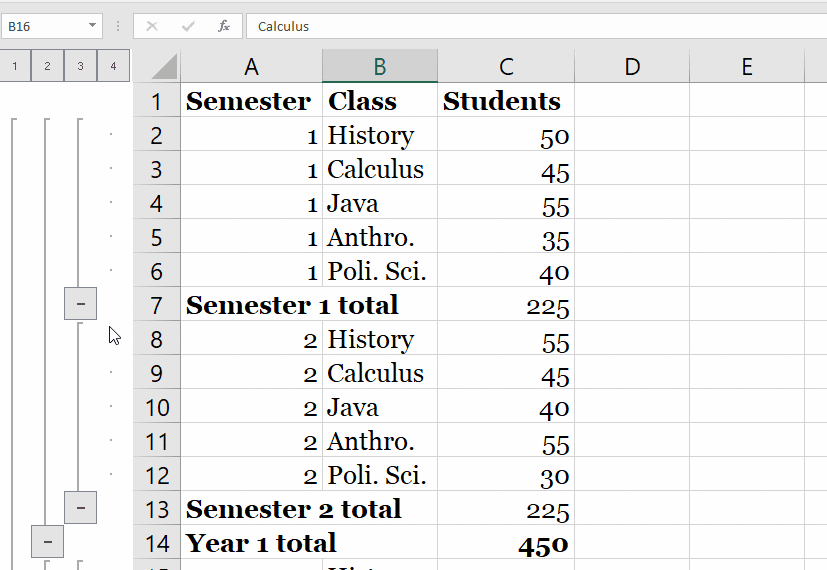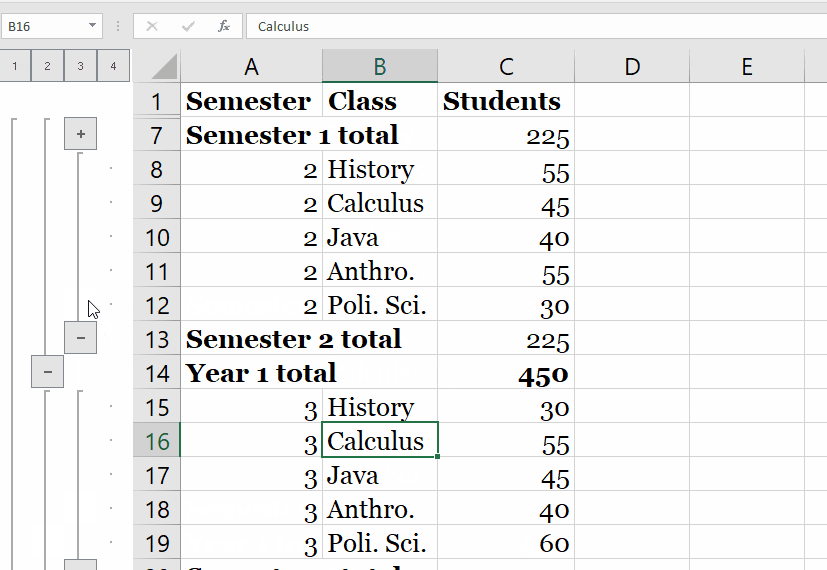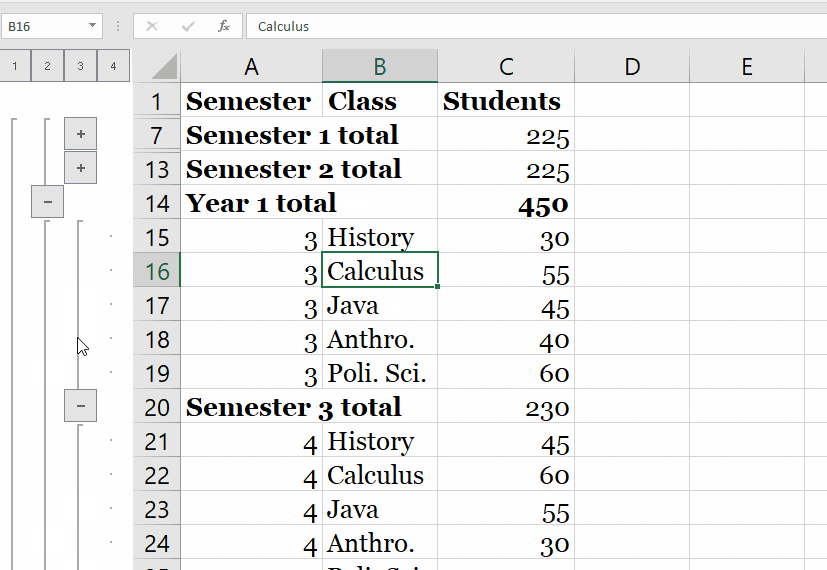
It then displays the first three rows of iris_projected. At this point, we have a lot of information at the individual level, but we'd like to summarize this at the state level by ethnicity, gender, and armed status. The researchers "calculated descriptive statistics for the proportion of victims that were male, armed, and non-White," so we'll do the same. The tally() function will be particularly helpful here to count the number of observations in each group. We're calculating this for each state as well as calculating the annualized rate per 1,000,000 residents.

This utilizes the total_pop column from the census_stats data frame we used earlier. Sometimes multiple pieces of information are merged within a single column even though it would be more useful during analysis to have those pieces of information in separate columns. To demonstrate, we'll now move from the msleep dataset to talking about another dataset that includes information about conservation abbreviations in a single column. Investing the time to learn these data wrangling techniques will make your analyses more efficient, more reproducible, and more understandable to your data science team. Let's concatenate two columns of dataframe with + as shown below.
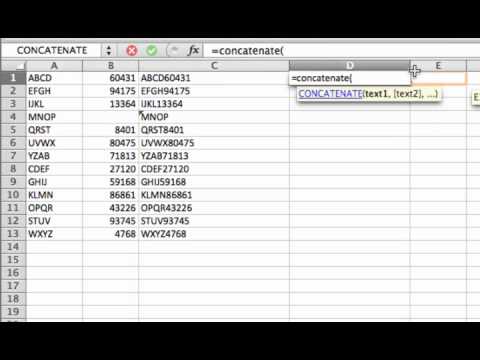
Paste() function takes up two or more column as argument along with "+" which concatenates them to a single column with "+" as separator. Very commonly you will want to put all of the variables you are using for a project into a single data frame, selecting a subset of columns using an arbitrary vector of names. Example 3-21 uses the as.ore subclass objects to coerce an ore.datetime data type into other data types.
Example 3-21 first extracts the date from the MYDATA$datetime column. The resulting dateOnly object has ore.date values that contain only the year, month, and day, but not the time. Example 3-2 selects rows from an ordered ore.frame object. The example first adds a column to the iris data.frame object for use in creating an ordered ore.frame object. It invokes the ore.drop function to delete the database table IRIS_TABLE, if it exists. It then creates a database table, with the corresponding proxy ore.frame object IRIS_TABLE, from the iris data.frame.
The example invokes the ore.exec function to execute a SQL statement that makes the RID column the primary key of the database table. It then invokes the ore.sync function to synchronize the IRIS_TABLE ore.frame object with the table and displays the first three rows of the proxy ore.frame object. Oracle R Enterprise provides functions that enable you to use R to prepare database data for analysis. Using these functions, you can perform typical data preparation tasks on ore.frame and other Oracle R Enterprise objects. The "Total" type is not really a formal type of health care coverage.

It really represents just the total number of people in the state. This is useful information and we can include it as a column called tot_pop. To accomplish this, we'll first store this information in a data frame called pop. First, the results of the skim() function indicate that some of our variables have lots of missing values. For instance, the variable Medal has 231,333 missing values. Generally, this is a place for concern since most statistical analyses ignore observations with missing values.

However, it is obvious that the missing values for the variable Medal are mainly because the athlete didn't receive any medals. However, we have missing values in the variables Height and Age. Since we are going to use these variables in our analysis in this lesson, observations with missing values for these two variables will be dropped from our analysis. Remember that NA is the most common character for missing values, but sometimes they are coded as spaces, 999, -1 or "missing." Check for missing values in a variety of ways. Beyond working with single strings and string literals, sometimes the information you're analyzing is a whole body of text.

This could be a speech, a novel, an article, or any other written document. In text analysis, the document you've set out to analyze are referred to as a corpus. Linguists frequently analyze such types of data and doing so within R in a tidy data format has become simpler thanks to the tidytext package and the package-accompanying book Text Mining with R. Another common issue in data wrangling is the presence of duplicate entries.

Sometimes you expect multiple observations from the same individual in your dataset. Other times, the information has accidentally been added more than once. The get_dupes() function becomes very helpful in this situation.
If you want to identify duplicate entries during data wrangling, you'll use this function and specify which columns you're looking for duplicates in. For these examples, we'll work with the airquality dataset available in R. Example 3-38 builds a simple smoothing model based on a transactional data set. As preprocessing, it aggregates the values to the day level by taking averages, and fills missing values by setting them to the previous aggregated value.
The model is then built on the aggregated daily time series. The function predict is invoked to generate predicted values on the daily basis. You can use the predict method to predict the time series of the exponential smoothing model built by ore.esm.

If you have loaded the forecast package, then you can use the forecast method on the ore.esm object. You can use the fitted method to generate the fitted values of the training time series data set. Provides distribution analysis of numeric columns in an ore.frame object of. Reports all statistics from the ore.summary function plus signed-rank test and extreme values.

Example 3-20 gets the year elements of the datetime column. The invocation of the unique function for year displays 2001 because it is the only year value in the column. However, for objects that have a range of values, as for example, ore.mday, the range function returns the day of the month. The result contains a vector with values that range from 1 through 31. Invoking the range function succinctly reports the range of values, as demonstrated for the other accessor functions.




No comments:
Post a Comment
Note: Only a member of this blog may post a comment.